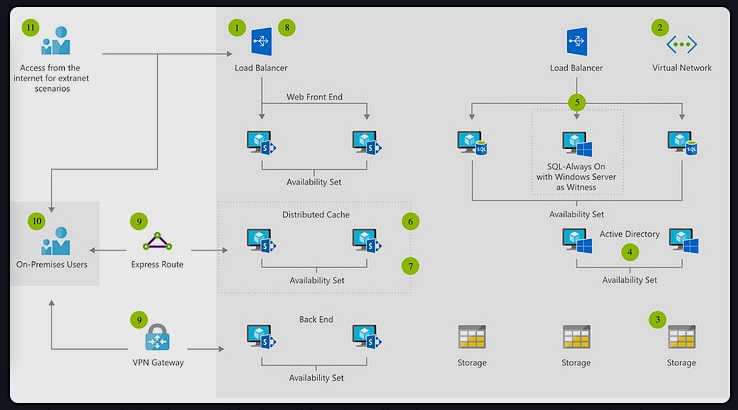
Curtalo: Das IT-Jahr 2013 wurde maßgeblich von einem Begriff geprägt: Big Data. Ist unser weltweites Datenaufkommen sprichwörtlich über Nacht explodiert oder spiegelt sich hier vielmehr eine kontinuierliche Entwicklung wider?
Dr. Wolfgang Martin: Einige Analysten haben diese Entwicklung tatsächlich schon in den 1990er-Jahren vorausgesagt. Schließlich zeichnete sich zu der Zeit mit der Verbreitung des WWW bereits ein erster markanter Punkt der großen Big Data-Welle ab, die dann in zwei weiteren Schüben zu dem werden sollte, was sie heute ist. Das verstärkte Aufkommen von Suchmaschinen vor knapp zwanzig Jahren war schon damals ein klarer Indikator für die wachsende Bedeutung von Daten und Informationen.
Seit den 90ern ist natürlich einiges passiert, es sind neue Technologien auf der Bildfläche erschienen. Mit den größeren technischen Möglichkeiten kam der zweite Schub der Big Data-Welle in Form von Social Media und Video, allen voran natürlich Facebook und Youtube. Und heute stehen wir mit den Informationen aus dem Internet-der-Dinge und der Machine-to-Machine-Kommunikation vor einer dritten Welle. Beispiele hierfür sind Smart Grids, also intelligente Stromversorgungsnetze, Smart Home-Konzepte oder auch immer intelligentere Autos.
Jeff Morris: Ich sehe das ähnlich: Die steigende Anzahl der Datenmengen ist nicht neu. Wir waren schon immer der Meinung, dass es Probleme bei der Verarbeitung von großen Datenvolumen geben könnte. Die Entwicklung neuer, dringend erforderlicher Lösungen wurde durch die Verbesserung von Speichertechnologien, Verarbeitungsleistung, Virtualisierung und Vernetzung sicherlich vorangetrieben. Das Kernproblem konnte damit jedoch nicht vollständig gelöst werden. Und heute entstehen durch die M2M-Kommunikation, also den Informationsaustausch von Maschine zu Maschine, tagtäglich neue Daten. Das verursacht eine neue Welle, die stark zu den wachsenden Volumen- und Geschwindigkeitsdimensionen von Big Data beitragen. Aber selbst das wäre vorhersagbar gewesen.
Curtalo: Braucht es wirklich neue Berufsbilder wie den viel beschworenen (Big) Data-Scientist, solange IT und Fachabteilung einen guten Job machen, sprich: produktiv zusammenarbeiten und stets die tatsächliche Relevanz von Big Data-Anwendungen im Auge behalten?
Shawn Rogers: Data Scientists bereichern die analytische Landschaft vor allem durch die Kombination zahlreicher Kompetenzen – eine Qualität, die ein traditioneller IT-Professional in der Regel nicht mitbringt. Data Scientists verstehen sowohl geschäftskritische Faktoren als auch die reinen Daten, mit denen sie arbeiten. Sie besitzen darüber hinaus die Fähigkeit, aus komplexen Analysen Informationen herauszufiltern, die unerwartete Einblicke und Ergebnisse hervorbringen. Ein Statistiker arbeitet in der Regel nicht mit übergreifenden analytischen Parametern und Werkzeugen. Vielmehr beschäftigt er sich damit, wie der Zugriff und die Analyse von Daten ganz allgemein erfolgen kann, um dezidierte Vorhersagen zu Einzelfragen treffen zu können. Eine solche Frage könnte beispielsweise lauten: „Wie viele Artikel haben wir gestern verkauft?” Ein Data Scientist hingegen würde Vorhersagemodelle entwerfen, um unerwartete Datenmuster zu identifizieren, auf deren Basis ein Unternehmen künftig den Verkauf einzelner Exemplare forcieren kann.
Damit will ich natürlich nicht generell sagen, dass alle Unternehmen mit großen Datenbeständen nun direkt einen Data Scientist einstellen müssen. Besteht eine gute Übereinstimmung zwischen IT und der „Line-of-Business“, ist dies oftmals schon ausreichend. Den neuesten Forschungen der Enterprise Management Associates (EMA) zufolge werden Data Scientists nach wie vor eher selten eingestellt. Die meisten Unternehmen greifen also weiterhin auf bestehende IT-Kompetenzen zurück.
Dr. Wolfgang Martin: In meinen Augen spielen bei der Frage, ob das Berufsbild des Data Scientists wirklich notwendig ist, zwei wesentliche Aspekte eine Rolle. Zum einen erfordern neue Technologien wie Hadoop und NoSQL mindestens die Weiterbildung der Mitarbeiter. Oft reicht ein Hadoop-Seminar jedoch nicht aus, da der Markt rund um Big Data-Technologien zurzeit noch recht unübersichtlich ist und zu viele Lösungen anbietet, die in den Kinderschuhen stecken. Hier sind Spezialisten gefragt, die damit umgehen können. Zweitens – und da kommen wir zum Kern der Sache – werden Unternehmen immer datengetriebener. Das heißt vor allem, dass die Vorstandsebene mehr von Analytics verstehen muss, als es heute häufig noch der Fall ist. Und genau hier kommt der Data Scientist zum Einsatz, der Kennzahlen interpretieren, analytische Ergebnisse für das Management nachvollziehbar aufbereiten und präsentieren kann. So gesehen ist er vor allem eine Art Kommunikator.
Jeff Morris: Ich würde es sogar noch etwas zuspitzen: Wenn wir nur zuschauen und den IT-Experten weitere 18 Monate Zeit geben, um Hadoop zu beherrschen und – getrennt davon – die Fachabteilungen mit dem Versuch alleine lassen, ihre Effizienz zu steigern, dann haben wir letztendlich einen Haufen von Excel-Usern, die vor einer unstrukturierten Sammlung von Hadoop-Dokumenten, Transaktionen und Aktivitätsprotokollen sitzen. Wir sind trotzdem oder gerade aufgrund der großen Notwendigkeit zuversichtlich, dass sich die Rolle des Data Scientists mit der Zeit aus Fachabteilungen und IT entwickeln wird.
Curtalo: Schlagwörter wie Skalierbarkeit, Integrierbarkeit und offene Schnittstellen gehören schon seit einiger Zeit fest in den Marketing-Kanon der IT-Dienstleister. Im Grunde sollte die Verarbeitung von Big Data unter diesen Bedingungen doch eigentlich kein Thema sein – oder etwa doch?
Dr. Wolfgang Martin: Diese Frage schließt direkt an die vorhergehende an, denn grundlegende Technologien wie NoSQL und Hadoop sind ja tatsächlich neu und extra für große Datenmengen entwickelt worden, insofern ist die Verarbeitung von Big Data schon anspruchsvoller. Es ist tatsächlich wieder Basisprogrammierung gefragt. Implementierungen und Schnittstellenintegration müssen tatsächlich häufig wieder über Sourcecode-Programmierungen erfolgen. Die Tatsache, dass viele Big Data-Plattform Open Source sind und permanent weiterentwickeln werden, macht die Angelegenheit nicht weniger komplex.
Jeff Morris: Es bleibt zu hoffen, dass es die Software-, Plattform- und Technologie-Anbieter den Unternehmen leicht machen werden. Dabei ist leicht oder einfach nicht gleichbedeutend mit kostenlos. Der Markt für freie Software zur Erstellung von Big Data-Infrastrukturen ist sehr dynamisch. Das ist erst einmal toll, kann aber auch dazu führen, dass sich die Entwickler schon heute auf die IT-Professionals von morgen konzentrieren. Auf lange Sicht ist Lösungsanbietern besser damit geholfen, sich auf den übergreifenden Mehrwert für ein Unternehmen zu konzentrieren und nicht nur die Effektivität der Infrastruktur vor Augen zu haben.
Shawn Rogers: Exakt. Denn der Schlüssel für eine effiziente Nutzung von Big Data liegt in meinen Augen in der Integration von und dem Zugang zu Daten. Ich sehe es allerdings so, dass ein Großteil der Unternehmen nicht auf Hadoop oder andere Plattformen als einzigen Arbeitsbereich für Big Data vertraut. Da die Plattformen in den Unternehmen mit jedem Tag vielfältiger werden, erreicht die Integration und das Management von Daten einen neuen Level an Komplexität. Zahlreiche Big Data-Projekte ziehen ihre Informationen aus den unterschiedlichsten Systemen – ein Umstand, der zugleich für eine enorme Belastung der betroffenen Systeme und ihrer umgebenden Infrastruktur sorgt. Deshalb werden Innovationen auf dem Gebiet der Integrationsmethoden zugleich die Entwicklung leistungsstarker Big Data-Lösungen vorantreiben.
Curtalo: Vielen Dank für das Gespräch und Ihre aufschlussreichen sowie richtungsweisenden Einschätzungen zum Thema Big Data!